
尝试学了一下 Node.js,虽说之前有学习使用过 React Native,但可能 Java 的根深蒂固,让我很难理解 JavaScript 和 Node.js 的思想。
都说写一个项目胜过看十天书,那就直接开练吧。
本想写个简单的后台熟悉一下,但是考虑到花费的时间可能会比较长,而且没什么方向,所以也是无从下手。
后来发现,Node.js 原来也可以写爬虫,那就写了个爬虫玩一下呗,也算是了却我一直想学 Python 写爬虫玩数据分析的心愿。
想了一想也不知道爬点啥,打开『Bing』搜索的时候突然想到,Microsoft 的『Bing』不是每天都更新壁纸的吗,那我能不能把『Bing』的壁纸爬下来呢?
好的开搞。
首先打开『必应壁纸』首页。

然后查看页面源代码,我使用的浏览器快捷键是 Ctrl+U,一按,结果没反应,右键菜单进入吧,右键,结果还是没反应。
卧槽,没想到『必应壁纸』的工程师居然做了这样的设置,不过的确用户体验是挺好的,只不过对我们这群“搞破坏的”不友好罢了。
既然不能查看页面源代码,那我能不能使用它的检查元素功能呢?
我的浏览器快捷键是 Ctrl+Shift+C,一按,有了!
这样看起来还是不太方便,既然检查元素的窗口已经打开了,那我能不能在这里进入页面源代码的窗口呢,Ctrl+U 尝试一下,欸,进去了。
先看一下『必应壁纸』首页的前端源代码,太凌乱了,它的图片链接也不好找,这样爬起来肯定就十分麻烦了,还是放弃吧,于是我把爬取对象转向了其他壁纸网站。
最终确定是『Stocksnap.io』。
为什么选它呢,首先它的页面除了壁纸以外并没有其他的多余元素,另外它的页面源代码可读性也比『必应壁纸』要高,图片链接也十分清晰,就它了。
接下来就是编写代码了。
编写代码之前肯定需要 Node.js 环境,直接去官网下载就可以了,而我在之前『Windows 平台 React Native 开发环境搭建笔记』中我已经安装过 Node.js 的环境了,所以就不用重新安装。
直接上代码。
var https = require('https');
var fs = require('fs');
var path = require('path');
var url = 'https://stocksnap.io';
// 检查目录中是否存在 images 文件夹,如果没有就创建
fs.mkdir('./images', function(err) {
if(err) {
console.log('Directory already exists.');
} else {
console.log('Directory creation success.');
}
});
https.get(url, function(res) {
var content = null;
res.on('data', function(chunk) {
content += chunk;
});
res.on('end', function() {
var reg = /src="(.*?\.jpg)"/img; // 全局匹配以【src=】开头,并以【.jpg】结尾的内容
var filename;
while (filename = reg.exec(content)) {
getImage(filename[1]); // 子匹配
}
});
});
function getImage(url) {
var imageName = path.parse(url).base;
var stream = fs.createWriteStream('./images/' + imageName);
https.get(url, function(res) {
res.pipe(stream);
console.log(imageName + ' download completed!');
});
}
解释一下源代码。
首先是引入各模块,这里由于需要发起 HTTPS 请求,需要写入文件,还需要分析 URL 的路径,所以就引入这三个模块。
接着需要一个目录来存储从网站上抓取下来的图片,为了不使文件夹里的文件类别凌乱,我就在项目的根目录创建一个名为「images」的文件夹用于存放,如果该文件夹已存在,则不需要重复创建,并在控制台中打印相关信息。
做好这些前期准备之后,就可以向『Stocksnap.io』发起 HTTPS 请求了。
先把整个页面的前端代码爬下来,如果数据量大的话,肯定不能一次性就能把所有的内容获取,所以使用拼接的方式把获取的片段连接完整。
当请求结束之后,会触发 end 事件,就在 end 事件中处理我们对其页面代码的解析。
我们再次来看看『Stocksnap.io』的前端代码:
比『必应壁纸』的代码清晰多了,定位一下我需要的内容,我需要的是图片,一般图片都会使用 <img> 标签。
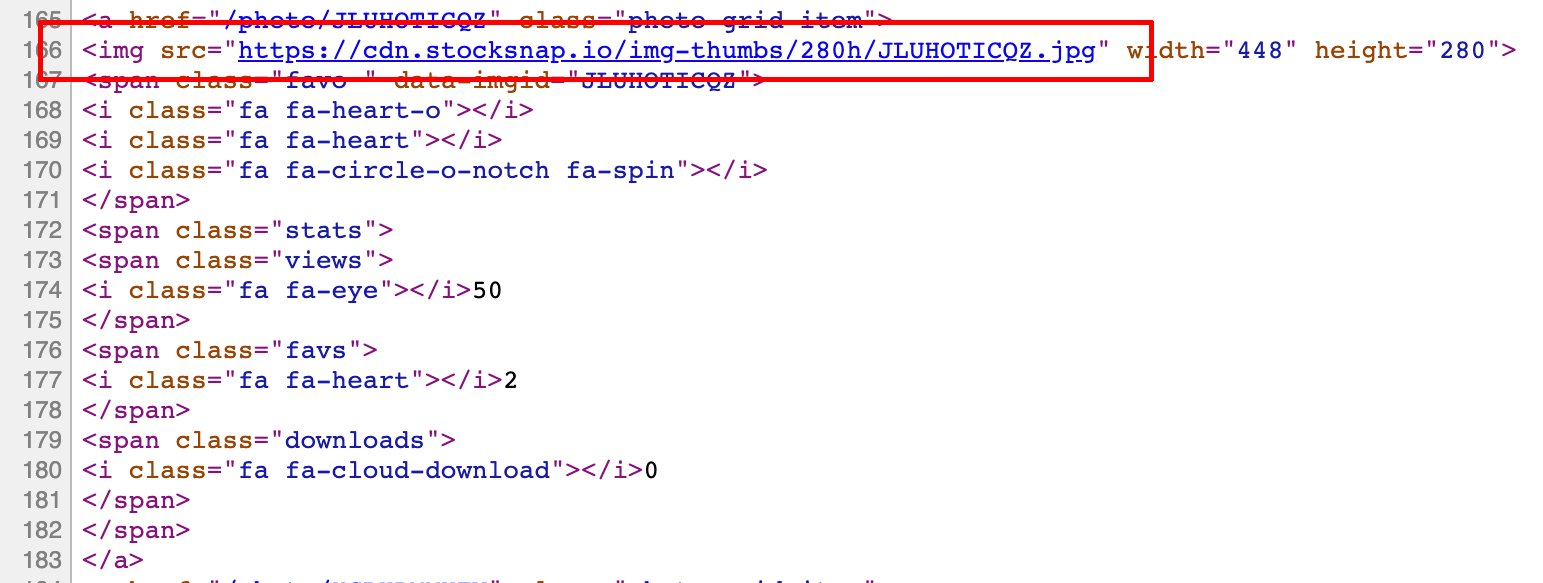
太好了,就一个完整的链接,不需要进行 URL 的拼接操作。
我只需要写个正则表达式将它匹配上就可以了,匹配规则也很简单,以 src=" 开头,并以 .jpg" 结尾的链接就是我们想要得到的图片链接。
根据之前在『常用正则表达式』中的参考,我们可以写出相应的正则表达式:/src="(.*?\.jpg)"/。
那后面的 /img 是什么意思呢?由于我对正则也是一知半解,就照搬一下网上的解释:
这些是模式修正符,是解说正则表达式模式中使用的修正符。其中,/i 表示模式中的字符将同时匹配大小写字母;/m 表示“行起始”和“行结束”除了匹配整个字符串开头和结束外,还分别匹配其中的换行符的之后和之前;/g 表示全局循环。
另外,/s 表示模式中的圆点元字符(.)匹配所有的字符,包括换行符;/x 表示模式中的空白字符除了被转义的或在字符类中的以外完全被忽略,在未转义的字符类之外的 # 以及下一个换行符之间的所有字符,包括两头,也都被忽略;/e 表示 preg_replace() 在替换字符串中对逆向引用作正常的替换。
当正则匹配完成后,匹配结果是一个数组对象,有两项,格式如下:
[
'src="https://cdn.stocksnap.io/img-thumbs/280h/G5Q3IISSYX.jpg"',
'https://cdn.stocksnap.io/img-thumbs/280h/G5Q3IISSYX.jpg'
]
可以发现它已经帮我们把图片的 URL 解析出来了,那我们只需获取解析好的链接进行下载即可。
根据数组的下标特性,下标为 1 的项就是图片的 URL。
在下载图片的函数中,调用 path 模块的 parse() 方法,可以对 URL 中的信息再次进行解析,得到如下 JSON 对象:
{
root: '',
dir: 'https://cdn.stocksnap.io/img-thumbs/280h',
base: 'G5Q3IISSYX.jpg',
ext: '.jpg',
name: 'G5Q3IISSYX'
}
其中,base 就是图片的文件名,通过连缀 .base 就可以获取了,获取的作用就是为了帮我们把下载的图片命名。
最后,通过管道流 pipe() 方法把图片下载下来就可以了。
如果程序没有报错,可以在项目根目录发现有一个「images」文件夹,里面已经有我们刚才爬下来的图片了。
不过,由于首页展示的只是缩略图,所以这个图片比较小,另外,由于页面使用的是滑动到底部自动加载的技术,所以爬取的数量也不会太多。
由于这对于我来说也只能算是一个练手的小项目,我也不打算继续深入研究了,如果有兴趣的朋友可以对其功能进行扩展以及改进。
我顺便也把这个项目放到了 Github 上,有兴趣的朋友可以去看看。