
什么是 EPUB
EPUB(Electronic Publication)是一种电子图书标准,由国际数字出版论坛(IDPF)提出,属于一种可以“自动重新排版”的内容;也就是文字内容可以根据阅读设备的特性,以最适于阅读的方式显示。它的文件扩展名为 .epub。
EPUB 的组成
EPUB 文件内部使用了 XHTML 或 DTBook(一种由 DAISY Consortium 提出的 XML 标准)来展现文字,并以 ZIP 压缩格式来打包文件内容。因此我们可以通过解压缩的方式来了解 EPUB 的构成。
下面这个是我从某电子书网站下载的两个 EPUB 文件解压图:
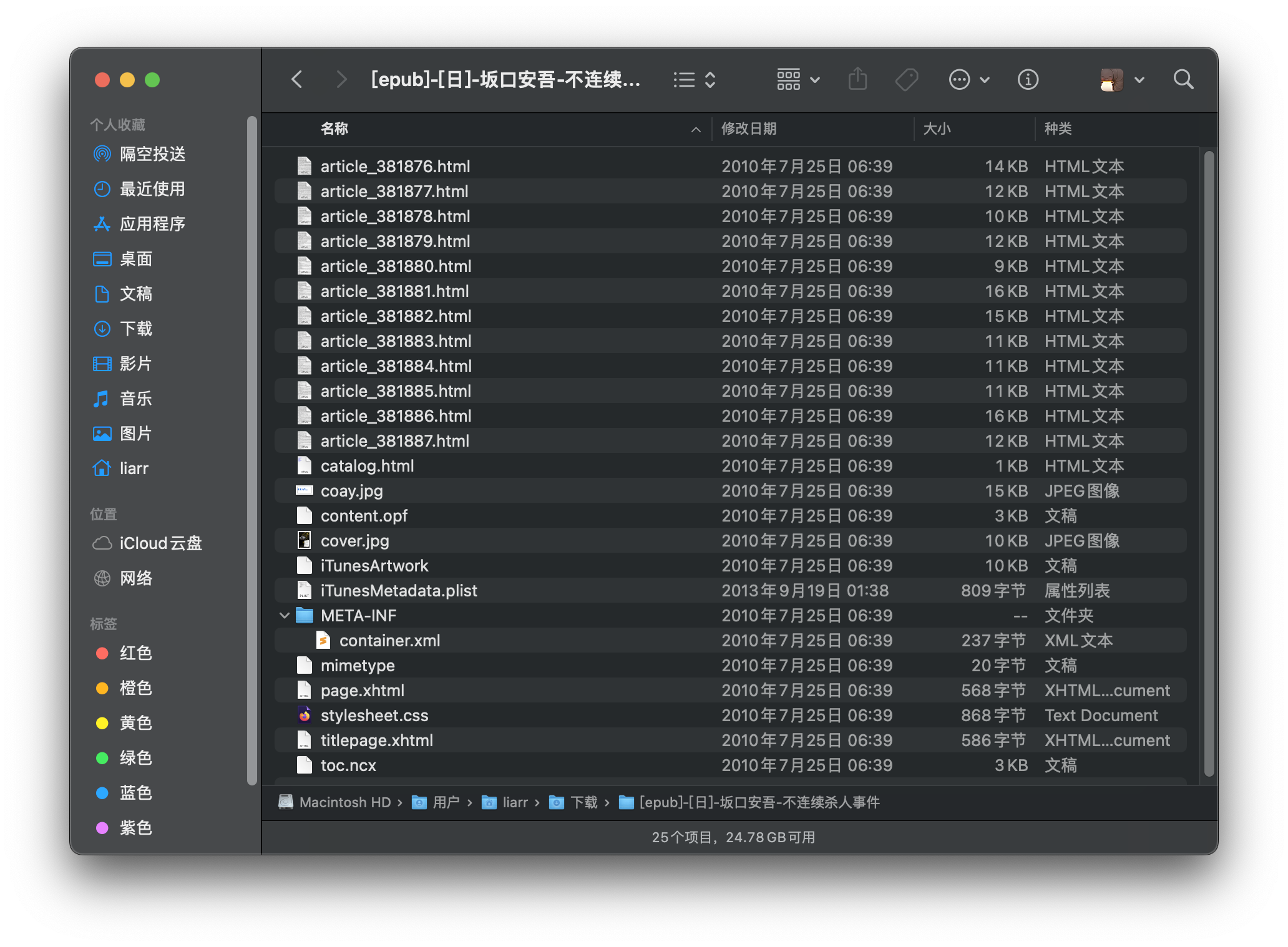
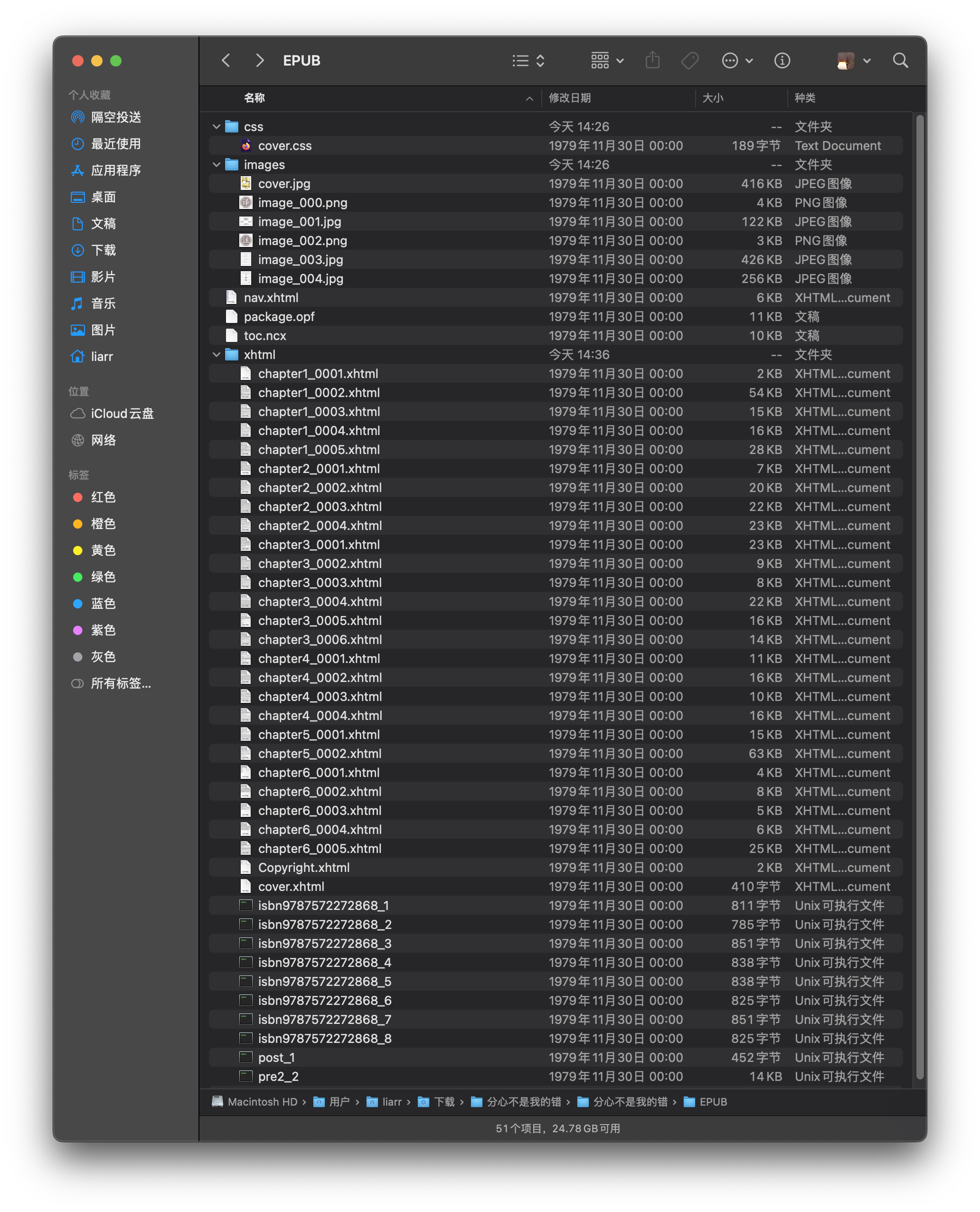
EPUB 的标准和规范一直在迭代,目录也有所差异,但文件组成是大同小异的,下面将逐一介绍各文件的作用。
MIMETYPE
它的文件名就是 mimetype,无文件扩展名,用于描述 EPUB 的 MIME,所以它的内容只有一行:
application/epub+zip
META-INF
用于存放特定文件,默认情况下里面只有一个 container.xml 文件,用于描述 OPF 的存放位置。由于 EPUB 的制作差异,META-INF 文件夹还可能包含数字签名和加密信息等文件,Java 开发者对这个目录应该不陌生。
container.xml 文件如下:
<?xml version="1.0"?>
<container version="1.0" xmlns="urn:oasis:names:tc:opendocument:xmlns:container">
<rootfiles>
<rootfile full-path="content.opf" media-type="application/oebps-package+xml"/>
</rootfiles>
</container>
该文件是必定存在的,它相当于是 EPUB 系统的指路牌。
OPF
OPF 文件是 EPUB 规范中最复杂的元数据,它用来定义 OPS 一系列内容组合到一起的机制。
常用的文件名是 content.opf,当然也可以是其他,但文件扩展名必须是 .opf,它内部其实是一个标准的 XML,下面是一个例子。
<?xml version='1.0' encoding='utf-8'?>
<package xmlns="http://www.idpf.org/2007/opf" version="2.0" unique-identifier="uuid_id">
<metadata xmlns:opf="http://www.idpf.org/2007/opf" xmlns:dc="http://purl.org/dc/elements/1.1/">
<dc:title>不连续杀人事件</dc:title>
<dc:creator>坂口安吾</dc:creator>
<dc:description>不连续杀人事件</dc:description>
<dc:language>zh-cn</dc:language>
<dc:date></dc:date>
<dc:contributor>COAY.COM [http://www.coay.com]</dc:contributor>
<dc:publisher>COAY.COM</dc:publisher>
<dc:identifier id="uuid_id" opf:scheme="uuid">8337</dc:identifier>
<dc:subject>不连续杀人事件</dc:subject>
</metadata>
<manifest>
<item href="article_381876.html" id="id381876" media-type="application/xhtml+xml"/>
<item href="article_381877.html" id="id381877" media-type="application/xhtml+xml"/>
<item href="article_381878.html" id="id381878" media-type="application/xhtml+xml"/>
<item href="article_381879.html" id="id381879" media-type="application/xhtml+xml"/>
<item href="article_381880.html" id="id381880" media-type="application/xhtml+xml"/>
<item href="article_381881.html" id="id381881" media-type="application/xhtml+xml"/>
<item href="article_381882.html" id="id381882" media-type="application/xhtml+xml"/>
<item href="article_381883.html" id="id381883" media-type="application/xhtml+xml"/>
<item href="article_381884.html" id="id381884" media-type="application/xhtml+xml"/>
<item href="article_381885.html" id="id381885" media-type="application/xhtml+xml"/>
<item href="article_381886.html" id="id381886" media-type="application/xhtml+xml"/>
<item href="article_381887.html" id="id381887" media-type="application/xhtml+xml"/>
<item href="catalog.html" id="catalog" media-type="application/xhtml+xml"/>
<item href="cover.jpg" id="cover" media-type="image/jpeg"/>
<item href="coay.jpg" id="ad" media-type="image/jpeg"/>
<item href="stylesheet.css" id="css" media-type="text/css"/>
<item href="titlepage.xhtml" id="titlepage" media-type="application/xhtml+xml"/>
<item href="page.xhtml" id="page" media-type="application/xhtml+xml"/>
<item href="toc.ncx" media-type="application/x-dtbncx+xml" id="ncx"/>
</manifest>
<spine toc="ncx">
<itemref idref="titlepage"/>
<itemref idref="page"/>
<itemref idref="catalog"/>
<itemref idref="id381876"/>
<itemref idref="id381877"/>
<itemref idref="id381878"/>
<itemref idref="id381879"/>
<itemref idref="id381880"/>
<itemref idref="id381881"/>
<itemref idref="id381882"/>
<itemref idref="id381883"/>
<itemref idref="id381884"/>
<itemref idref="id381885"/>
<itemref idref="id381886"/>
<itemref idref="id381887"/>
<itemref idref="page"/>
</spine>
<guide>
<reference href="titlepage.xhtml" type="cover" title="封面"/>
<reference href="catalog.html" type="toc" title="目录"/>
</guide>
</package>
它由四个部分组成:
<metadata>:元数据信息。包含书名、作者、出版社等信息,其中<dc:title>和<dc:identifier>这两个数据是必须的。按照 EPUB 规范,<dc:identifier>由数字图书的创建者定义,必须唯一,对于图书出版商来说,这个字段一般包括 ISBN 或者 Library of Congress 编号。<manifest>:文件列表。列出电子书中包含的资源文件(HTML、CSS、NCX、图片等),它的每一子项都包含了文件 ID、相对路径以及媒体类型。<spine>:文档线性阅读顺序。其中toc属性指向<manifest>中.ncx文件的id,子项的idref属性同样指向<manifest>中的文件id。<guide>:电子书指引页。比如封面、目录、序言等,通过href属性指向文件路径。
NCX
NCX 定义了数字图书的目录表,复杂的图书中,目录表通常采用层次结构,包括嵌套的内容、章节等。
它的文件名通常是 toc.ncx,是一个逻辑目录,内部也是一个标准的 XML,下面是一个例子。
<?xml version='1.0' encoding='utf-8'?>
<ncx xmlns="http://www.daisy.org/z3986/2005/ncx/" version="2005-1">
<head>
<meta name="dtb:uid" content="coay_8337"/>
<meta name="dtb:depth" content="2"/>
<meta name="dtb:generator" content="COAY.COM [http://www.coay.com]"/>
<meta name="dtb:totalPageCount" content="0"/>
<meta name="dtb:maxPageNumber" content="0"/>
</head>
<docTitle><text>不连续杀人事件</text></docTitle>
<docAuthor><text>坂口安吾</text></docAuthor>
<navMap>
<navPoint class="chapter" id="article_381876" playOrder="1">
<navLabel><text>第一章 丑恶万分的人际关系(1)</text></navLabel>
<content src="article_381876.html"/>
</navPoint>
<navPoint class="chapter" id="article_381877" playOrder="2">
<navLabel><text>第一章 丑恶万分的人际关系(2)</text></navLabel>
<content src="article_381877.html"/>
</navPoint>
<navPoint class="chapter" id="article_381878" playOrder="3">
<navLabel><text>第二章 意外的访客</text></navLabel>
<content src="article_381878.html"/>
</navPoint>
<navPoint class="chapter" id="article_381879" playOrder="4">
<navLabel><text>第三章 不速之客</text></navLabel>
<content src="article_381879.html"/>
</navPoint>
<navPoint class="chapter" id="article_381880" playOrder="5">
<navLabel><text>第四章 第一位被害者</text></navLabel>
<content src="article_381880.html"/>
</navPoint>
<navPoint class="chapter" id="article_381881" playOrder="6">
<navLabel><text>第五章 猫 铃(1)</text></navLabel>
<content src="article_381881.html"/>
</navPoint>
<navPoint class="chapter" id="article_381882" playOrder="7">
<navLabel><text>第五章 猫 铃(2)</text></navLabel>
<content src="article_381882.html"/>
</navPoint>
<navPoint class="chapter" id="article_381883" playOrder="8">
<navLabel><text>第六章 第二桩案件</text></navLabel>
<content src="article_381883.html"/>
</navPoint>
<navPoint class="chapter" id="article_381884" playOrder="9">
<navLabel><text>第七章 身为侦探小说迷的老政客</text></navLabel>
<content src="article_381884.html"/>
</navPoint>
<navPoint class="chapter" id="article_381885" playOrder="10">
<navLabel><text>第八章 唯一的不在场证明</text></navLabel>
<content src="article_381885.html"/>
</navPoint>
<navPoint class="chapter" id="article_381886" playOrder="11">
<navLabel><text>第九章 火葬归途</text></navLabel>
<content src="article_381886.html"/>
</navPoint>
<navPoint class="chapter" id="article_381887" playOrder="12">
<navLabel><text>第十章 疯子大集合</text></navLabel>
<content src="article_381887.html"/>
</navPoint>
</navMap>
</ncx>
它有如下几个部分组成:
<head>:该标签内主要包含四个<meta>元素:dtb:uid:数字图书唯一 ID。一般和 OPF 中的<dc:identifier>对应。dtb:depth:反映目录表中的层次深度。dtb:totalPageCount:仅用于纸质图书,保留0即可。dtb:maxPageNumber:仅用于纸质图书,保留0即可。
<docTitle>:图书标题。一般和 OPF 中的<dc:title>对应。<docAuthor>:图书作者。一般和 OPF 中的<dc:creator>对应。<navMap>:图书目录。包含多个<navPoint>,内部又包含下列元素:playOrder:文档阅读顺序。和 OPF 中<spine>的子项顺序相同。<navLabel>:章节标题。<content>:指向文件路径。和 OPF 中<manifest>子项配置的路径一致。
资源文件
除了上面介绍的几个重要文件外,剩下的几乎都是资源文件。包括 HTML/XHTML、CSS、JPG、PNG、SVG 等等。HTML/XHTML 则是书籍的内容,里面会引用 CSS 和图片等。
这些文件没有明确的路径要求(事实上除了 mimetype 和 container.xml 两个文件有明确的要求外,其他文件都没有明确的路径要求),这也是为什么文章开头的两个 EPUB 目录会相差这么大。
OPF <spine> 和 NCX <navMap> 的区别
两个文件都描述了文档的顺序和内容,这很容易混淆。
OPF <spine> 描述了书中各个章节是如何实际连接起来的,比方说翻过第一章最后一页就到第二章第一页。
NCX <navMap> 在图书一开始描述目录。目录肯定会包含书中主要的章节,但是还可能包含没有单独分页的小节。
NCX 包含的 <navPoint> 元素通常比 OPF <spine> 中的 itemref 元素多。一般情况下,<spine> 中的所有项都会出现在 NCX 中,但 NCX 可能更详细。
开发
基于以上知识,你完全可以自行构建一本 EPUB 电子书了。所以在此我不打算介绍 EPUB 的制作流程。
简单说一下 EPUB 阅读器的制作。
由上面的介绍得知,EPUB 内容是依靠 HTML/XHTML 渲染的,以 Android 为例,我们就可以借助 WebView 加载。
首先需要解压 EPUB 文件,取出 META-INF 中的 container.xml 文件,解析获取 OPF 文件路径,再取出 OPF 文件进行解析,获取元数据、资源、阅读顺序等信息,最后将 HTML/XHTML 按顺序交给 WebView 加载。
因为上面介绍的配置文件基本都是 XML,你可以借助之前介绍的 Dom4J 完成解析。
如果需要交互功能,可以向 WebView 中注入 JavaScript 来完成。